When someone takes an AncestryDNA test, we compare their DNA to the DNA of the hundreds of thousands of other test-takers in the AncestryDNA database. We’re looking for “DNA matches” — people who share DNA with one another, and so might be relatives.
The main idea behind identifying a DNA match is to look for pieces of DNA that two people both have because they each inherited it from a recent common ancestor. In a previous blog post about last year’s update to DNA matching, we detailed the steps we take to turn one’s genetic data, and that of others in the AncestryDNA database, into these suggested DNA matches.
One of those steps is to identify pieces, or segments, of DNA that are likely to be identical between pairs of people. But if two people have identical DNA, it doesn’t necessarily mean that they inherited it from a recent shared ancestor. Pieces of DNA could be identical between two people because they are of the same ethnicity or population — meaning that they (and many others from that same population) share DNA that they inherited from a distant ancestor who lived much longer ago.
So in order to find DNA matches that are due to recent ancestors, we need a filtering step. At AncestryDNA, we use an algorithm developed by the science team called Timber. Its basic idea is that if two people appear to have identical DNA at a particular place in the genome, but they also appear to have identical DNA with thousands of other people at that particular place, then the shared DNA between the two people was probably inherited from a more distant ancestor (or a distant set of ancestors). In other words, that segment is probably not relevant to a common ancestor within the last 6 or 10 generations.
So in cases like this, Timber might filter out those identical pieces of DNA entirely – and not consider them when deciding whether two people are related. Looking at results from over 300,000 people, we’ve found that while Timber filters out a majority of small identical segments (< 8 cM), it often also filters out larger segments (even those over 15 cM). See the chart below.
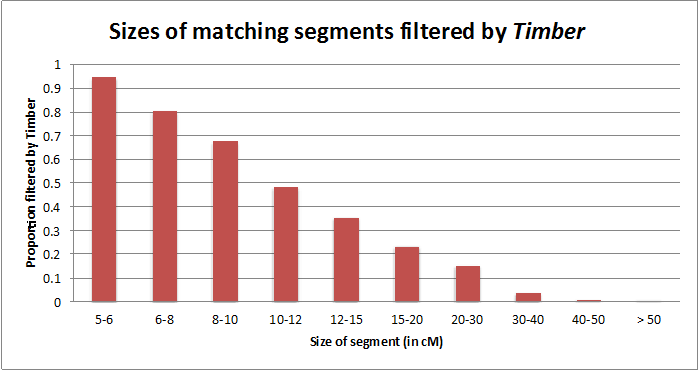
What this chart clearly shows is that when trying to identify DNA matches who share DNA from a recent common ancestor, there is much more to it than the sizes of the identical DNA segments. Longer identical segments don’t necessarily prove that two people have a recent common ancestor. DNA matching among hundreds of thousands of people has shown that even long identical segments can indicate shared ancestry, shared population history, or a more distant shared ancestor.
The good news is that by using a filter like Timber, we can find shared DNA that is more likely to be due to recent common ancestors. It’s important to keep in mind that identifying identical segments and filtering them are both statistical decisions; so, it is difficult to base conclusions on any particular shared segment of DNA alone. But in aggregate, a large number of experiments on data from real families as well as computationally engineered ones have shown that Timber is exceptionally powerful at removing DNA matches that are due to more distant relationships.
Since Timber is powered by DNA matching results among hundreds of thousands of people, Timber is a personalized filter that is uniquely possible with AncestryDNA’s enormous database. And as a result, AncestryDNA test-takers can receive DNA matches that are more reliable for genealogy research.