I recently attended the three-day biennial International Conference on Document Analysis and Recognition (ICDAR-2013) in Washington, DC. ICDAR is sponsored by the International Association for Pattern Recognition and is the premier event for those working in the field of Document Analysis (DA). Primarily the attendees are from corporate and university labs; they are professors, graduate students and technologists involved in businesses relating to DA technologies. Since DA is such an important set of technologies for our work in the Image Processing Pipeline (IPP), I have decided to interrupt my regularly scheduled series, Image Processing at Ancestry.com, and present a brief introduction to a few key concepts in DA. In my next post in this mini-series I will share with you some of what I learned at ICDAR-2013 and conclude with some of the factors I think have caused, or at least contributed to, the dramatic improvements we’ve seen in this field in the last few years.

What is Document Analysis (DA)?
Perhaps the best way to think about DA is to contrast image processing with image analysis. In the diagram in Figure 1, both the blue “Image Processing” block and the green “Image Analysis” block take an image as their input. Image processing applies operations to the input image to produce an output image that has been cropped, deskewed, scaled, or enhanced in some way. The point of image analysis, by way of contrast, is not to produce an output image, but to derive or extract information from the input image. It’s about trying to get at the semantics or extract the content from the image.

Figure 1. Image Processing vs. Image Analysis
DA is a family of technologies shown in Figure 2 as green components and arranged in layers, the foundation of which is a set of blue image processing components, reflective of the fact that good image processing always precedes any kind of image analysis task.
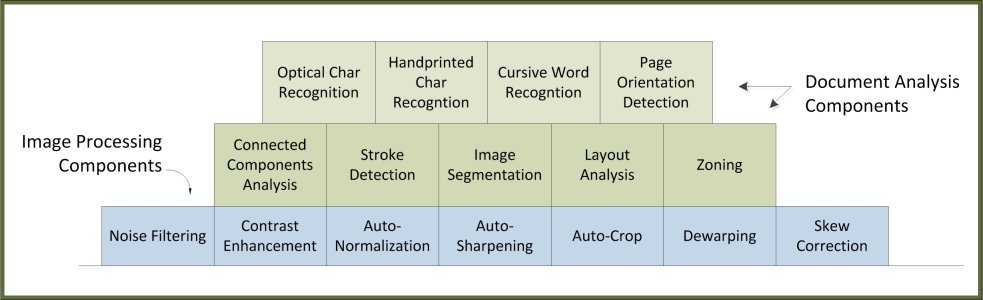
Figure 2. Document analysis technologies shown as green components on a foundation of blue image processing components.
The technology components (mathematical operations and learning algorithms) involved in doing any kind of DA task might appear to be simple and straightforward. In fact, the individual components can actually be described quite succinctly. However, when you go a bit beneath the surface, things quickly get very murky. Implementing a system with some of the common DA technologies can turn out to be incredibly complex. Characterizing the component interactions and controlling their behavior under real-world conditions is anything but straightforward. This is why DA is considered to be a difficult and unsolved problem.
In spite of these challenges, and the complexities that make an attempt at a “brief overview of the technology” somewhat doomed from the start, I will focus this post on four principles that have helped guide our work in developing DA technology and applications at Ancestry.com. I think these principles get to the core of how to think about DA. Also, I believe these four principles are general enough that sharing them here might be a good way to introduce DA without presenting a bunch of equations or pseudo-code.
Principle 1: The text assumption. DA is sub-field of image analysis in which the techniques we use assume that the image contains text or text-like structure in table form. This text assumption is a pretty strong constraint. But to the extent that it’s valid for your domain, it dramatically simplifies all aspects of the analysis. We are expecting words, not a photograph of a flower, a person’s face, or a topographical map. Documents have regularities that can be learned. Natural images do not. Since we are dealing with text, there are a myriad of tools available for processing this text. For instance, in 2006, Google released a one trillion word corpus with frequency counts for all sequences up to five words. Documents allow for language models, which can guide how your system processes and interprets the various low-level probabilities from stroke and character classifiers.
Principle 2: Consider content and structure. Documents are typically structured according to some hierarchy – a page is composed of regions, each of which have zones and/or fields. The content that we wish to identify and extract is embedded in this structure. Consider, for example, the death record in Figure 3 below. It is extremely difficult to create an algorithm that can make much sense of this document, much less be able to accurately extract the fields of interest without first building a model of, and then traversing through the document’s structure.

Figure 3. Death certificate as an example of a document in which you must understand the structure in order to extract the content.
The content and structure principle guides how we view or evaluate component or system-level functionality: these two aspects must not be blurred, or worse, treated as if they are similar kinds of things. The content in a document is embedded in structure, but content is not like structure. Any real DA based system must have components for dealing with both the content and the structure.
Principle 3: Content is bottom-up hierarchical. Almost without exception, the content of interest in a document is comprised of text that is built up from a hierarchy. Content is extracted from the bottom-up. The bottom of the hierarchy is a component, which is a small piece of ink from a pen stroke, part of a machine-printed character, or part of a machine-printed line. The diagram in Figure 4 illustrates the bottom-up hierarchy for some example content from a document. In words, this diagram says the following: components combine into primitives which are organized into words, which are organized into phrases. The content hierarchy is bottom-up because that approach has proven to be the most reliable way to find and extract content. Start with a search for components that form high-likelihood primitives (characters), which are then used to form candidate words and phrases, which are scored against runner-up primitive combinations.
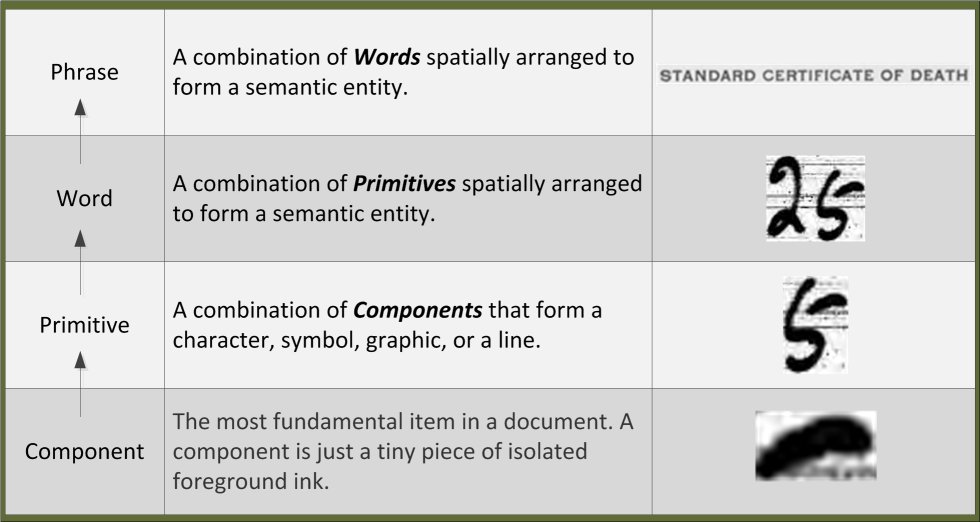
Figure 4. The content elements form a bottom-up hierarchy.
A zoomed-in snippet shown in Figure 5 contains strokes and lines, which unfortunately don’t play well together. This figure illustrates how stroke components combine to form characters (numerals). But you can also see how machine-printed lines might interfere with an algorithm attempting to isolate a connected component to form a character hypothesis. Whenever possible, lines are subtracted out of a region before an attempt is made to isolate characters for recognition. But in general, stroke detection (determining a character from one or more components), is a hard problem that currently for handwritten character strokes is not even close to being accurate enough to be practical to deploy in a real DA system.

Figure 5. Zoomed-in snippet containing strokes and lines.
Principle 4: Structure is top-down hierarchical. Almost without exception, the structure of a document is hierarchical. This structure is imposed from the top down. Structure helps locate or interpret the content to be extracted. The diagram in Figure 6 illustrates how the structure is a top-down hierarchy. In words, this diagram says the following: a page consists of regions, which each consist of zones, which each consist of fields. This structure is modeled as a top-down process because that is the only approach that has been demonstrated to be effective on a variety of document types. A page is segmented into homogeneous regions (sometimes with the help of separator lines, regular white space, or other similar cues) that each lead to high-likelihood zones and fields.

Figure 6. The structure elements form a top-down hierarchy.
Two snippets from the death certificate in Figure 3 are shown below in Figure 7 to illustrate these two hierarchies. The content item (orange) are the information items we wish to extract from the document and the structure items (green) are used to locate or interpret the content elements.

Figure 7. Two snippets from a death certificate that illustrate the content (orange) and the structure (green).
As a final observation, I include an example of a common error in structure detection. The zoomed-in snippet in Figure 8 illustrates one of the challenges in detecting regions. Notice that the text in the red box is tightly clustered in a region bound on the left with what could be separator lines, but the region shown in the red box is completely wrong. The correct region is shown with the green box.

Figure 8. An example of how an incorrect segmentation (red box) might group all of the names into a single region. Correct segmentation (green box) properly group fields in a row.
The source of this region detection problem was its failure to detect that this snippet is really a table. To a human observer it’s clear that the machine-printed text at the top of the snippet is a set of column headers. When viewed as a table with records represented by rows and the fields of the record represented by columns, then the task is fairly straightforward to automatically extract the fact that Ella Flynn is single and arrived in the U.S. on Feb. 1, 1872. Of course this assumes that a character recognizer can correctly extract the handwritten name Ella Flynn and the handwritten date, Feb. 1, 1872. Unfortunately, this is beyond the capabilities of the current, state-of-the-art stroke recognition systems.
In my next post I will present what I learned from ICDAR-2013 with an eye towards assessing the current state of DA technologies.