This post is the third in a series about the Ancestry.com Image Processing Pipeline (IPP). The IPP is the part of the content pipeline that is responsible for digitizing and processing the millions of images we publish to our site. In part 1 of this series, The Good, the Bad, and the Ugly, I gave a very general overview of IPP. In part 2, Living in the Mesosphere, I used a paper-stacking analogy to provide a sense for the volume of images we process in the IPP. In this post I describe at a very high level the challenges related to the digitizing part of the pipeline and in future posts I will delve more deeply into the processing part of the pipeline.
The following diagram shows the sequence of operations that occur in converting a paper document to a digital image.
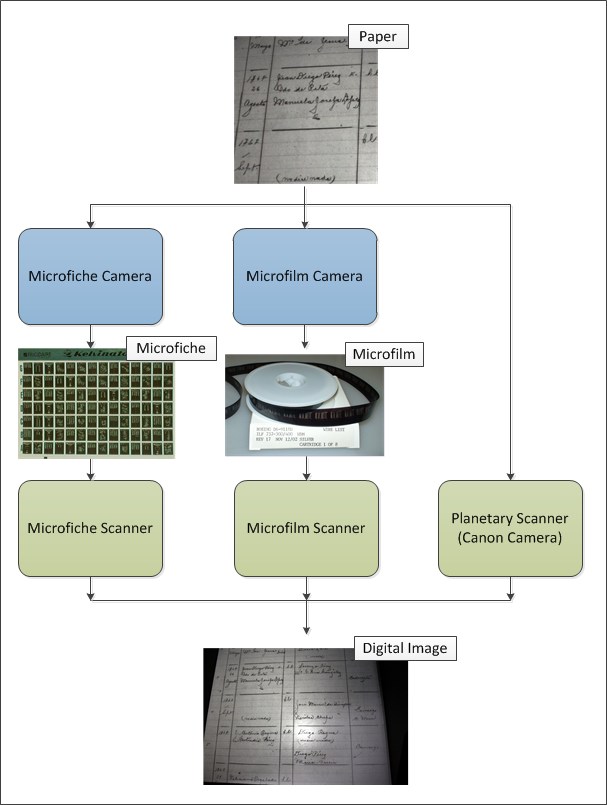
In this multi-step process of converting a paper document into a digital image, there are a number of “destructive operations” that can and frequently do occur, which leaves the image with artifacts that make the content difficult to read. Some of these destructive operations are listed in the following diagram.
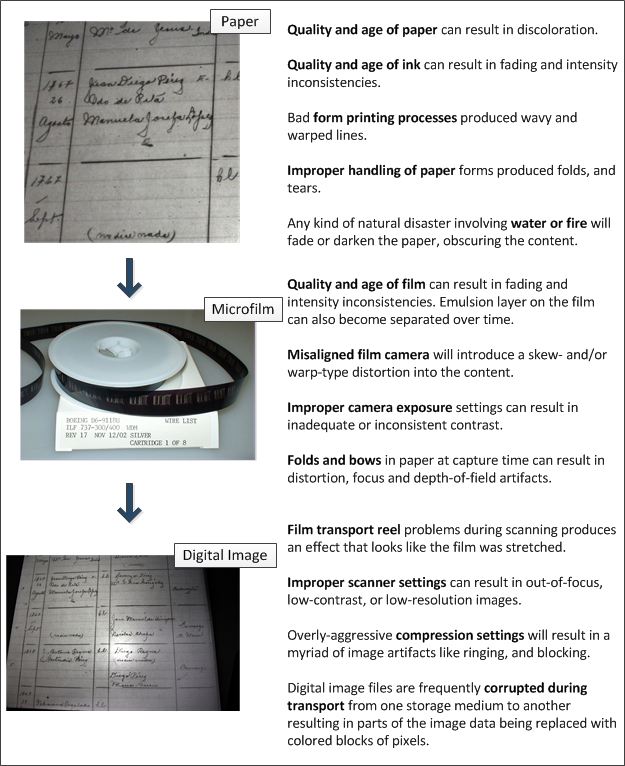
After considering all of the destructive operations that can happen as a paper document is converted into a digital image, the obvious questions are: (1) Is it possible to undo this damage? And if so, (2) How would one go about undoing this damage to make the content in these images more legible?
The process of trying to correct or compensate for these kinds of (destructive) operations is referred to as an “Inverse Problem“. Inverse problems occur in various fields of applied mathematics – they are well-studied, notoriously difficult, and can roughly be described as follows.
We start with an observation (the digital image) and we attempt to invert or reverse the effects of operations, which we cannot directly observe. But worse, these operations are non-linear and compounding with parameters that can’t be measured with any degree of accuracy. In our specific case this means that there is no generalized, closed-form solution to make faded, skewed, warped, low-contrast images look new again. Inverse theory provides little in the way of specific, practical guidance, but it does suggest a set of strategies (that have been shown to be successful in other fields) which we have attempted to follow in the IPP:
- Constrained. If we constrain ourselves to only attempt to optimize for a single aspect of the problem, which in our case is legibility, we are much more likely to arrive at acceptable results. However, this could, as an example, result in an image with handwriting or machine printed text that is generally deemed to be more legible but at the cost of a darkened or discolored image.
- Approximate. Inverse problems are considered ill-posed, which means that approximate solutions are the best we can hope for. A practical example of this (which will be discussed in detail in a future post) is to be very conservative in the use of an operation like sharpening. Attempting to get the parameters necessary to do an exact sharpening operation is likely to backfire and damage as many images as it helps.
- Adaptive. Instead of attempting to use static, global parameters, we allow our operations to be locally-adaptive, which means the parameters driving a particular operation, say, an auto-crop, are determined by local, image-specific measurements. This is more computationally expensive, but as a guiding principle it has shown to be the correct approach.
The image content that Ancestry.com makes available on our site typically arrives at our facilities as film or paper. We scan this media into digital images and then attempt to correct all of the damage that was done before it arrived to be digitized. Hopefully I’ve shed some light on the myriad of things that can damage the content in the early stages of its conversion from paper, and in general terms, provided the context for the processing we do in the IPP, which I will discuss in more detail in my future posts.
Credits
In both diagrams in this blog post I include an image of a roll of microfilm. Ianaré Sévi for Lorien Technologies is the copyright holder for this image. He has made it available under the Creative Commons Attribution-Share Alike 2.5 Generic license. Also in both of these diagrams I include two images, one labeled “Paper” and the other labeled “Digital Image”. These two images were extracted from an image that is used courtesy of James Tanner, http://genealogysstar.blogspot.com