A company’s data set is a unique asset and it is very advantageous for companies to know what one of its most valuable assets looks like to make product and business decisions. That is where data scientists come in: we like to study data. At Ancestry.com, we have a large and unique set of data, which includes over 55 million family trees our members have built on the site. In this blog post, we will restrict our discussion to a recent area of exploration for our data science team: graphs based on parental relationships at Ancestry.com.
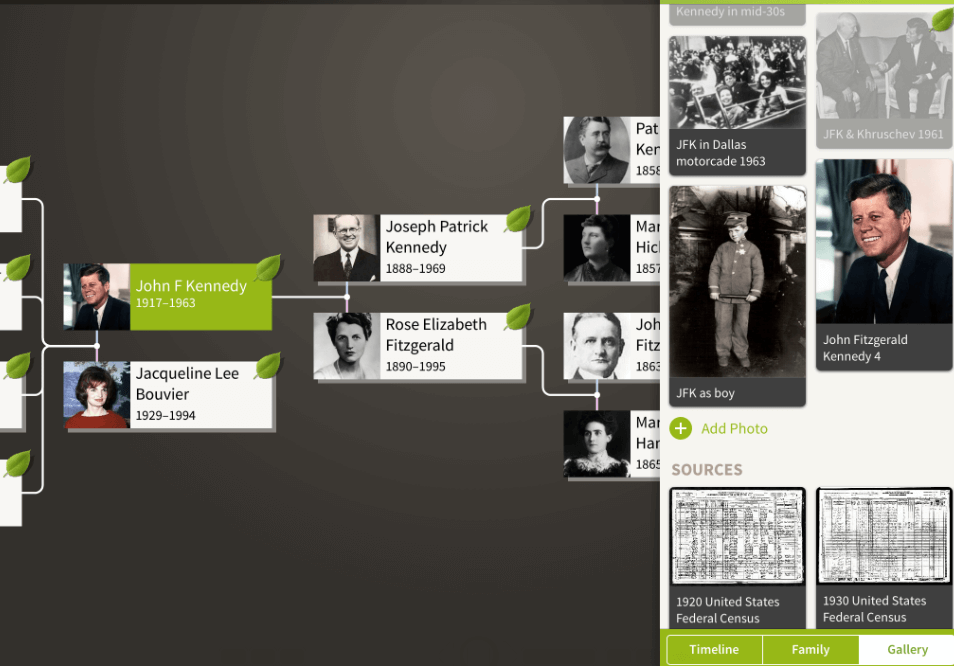
Family trees are one of several types of data that Ancestry.com has. They consist of nodes (people), and edges (relationships) between them. The Ancestry.com system supports the storing of multiple types of information in nodes, i.e., a person’s first and last name, date of birth, place of birth, etc. There are two types of relationships possible between nodes – parental and marriages. Note that parental relationships are represented by directed edges, going from parent to child. Here is a look at JFK’s public tree via the Ancestry app:
Every person in a family tree has a tree of her/his ancestors (a pedigree) and can have a tree of her/his descendants. But each ancestor, in turn, can also have a tree of their descendants, and every descendant can have a tree of their ancestors as well, thus making a graph structure more complex. The possibility of intermarriages introduces semi-cycles (undirected cycles) to the graphs, i.e. multiple directed paths – “blood lines” – from one person to another.
Though it’s called a “family tree,” from the graph-theoretic point view, “family tree” is not a tree, but a directed acyclic graph – DAG (tree definition requires existence of a unique path between every pair of nodes). The graph is acyclic, since no person can be at the same time his own parent. We will continue to use the term “family tree,” keeping in mind these discussed issues.
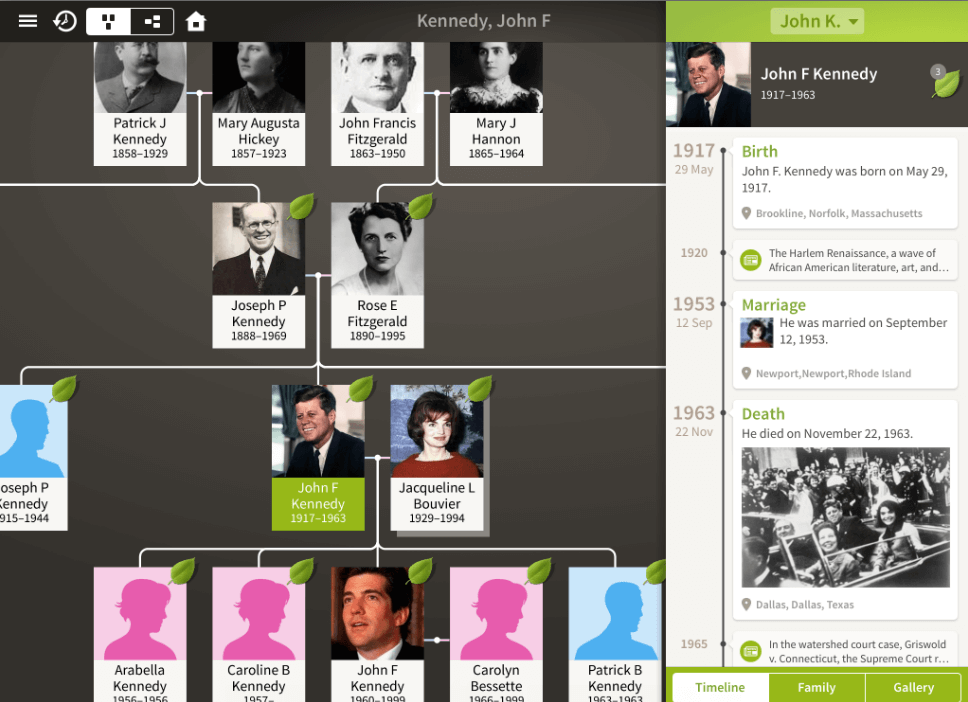
There exist multiple ways to visually represent family trees. The most common is a “pedigree ” or an “ancestry chart” view, showing all ancestors of a selected person. In an ancestry chart, a selected person will be positioned at the bottom and the expanding tree-like structure starts from that person and goes up. In these charts the top of the tree is wider than the bottom. Assuming no common ancestors, this would be a perfect binary tree. Sometimes an individual is positioned at the very left and the ancestors appear to the right. Here is an example of such a layout from a JFK public tree at Ancestry.com:

Though the pedigree view is a very convenient format for viewing information about individuals and their relationships with closest relatives and recent ancestors, it is hard to use when one wants to see the entire family tree. In general, tree is a planar graph, i.e., it can be drawn in 2D without any edge intersections. Family graphs locally look like a tree and that makes the “pedigree chart” an excellent viewing tool. At the same time, since they are really not trees, when trying to draw them completely, one runs into problems typical for large graph layout Another well-known problem in visualizing large trees is their quick local densification, related to the exponential growth rate of a number of nodes with every generation.
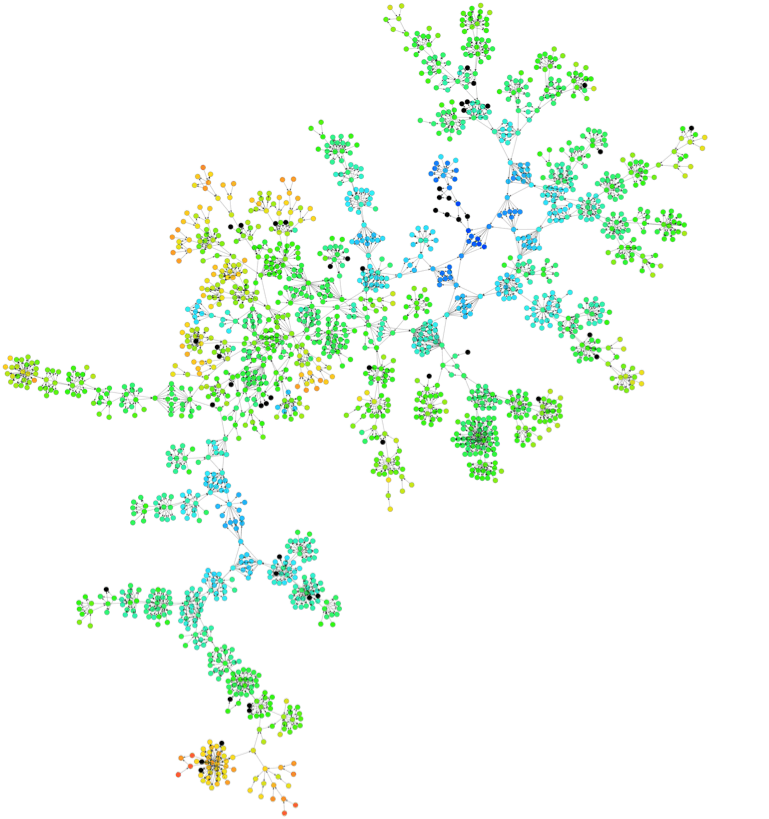
Some of the trees in the Ancestry.com collection reach tens of thousands of nodes in size and stretch for more than fifty generations. The following figure shows the histogram of the distribution of the number of trees versus their size. It clearly follows Zipfian (power law) distribution, i.e., most of the trees are small, but there are also very large trees in the collection. Trees with 1,000-10,000 nodes are pretty common.

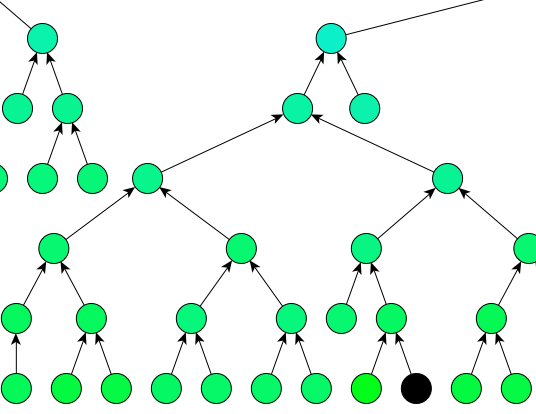
The family tree view is also a layered graph, whose layers are family generations (in a layered graph, edges run between successive layers). This property can be used for visualizing and color-coding the graph. In the picture below, the nodes are color-coded according to the person’s date of birth (black means no data). This graph places newer generation on top and older generation at the bottom and arrows point from a parent to a child; both parents usually placed on the same height in a graph since they belong to the same generation layer. It is easy to see, that color-coding follows the tree layers structure. In this particular family tree, only one branch goes very deep in time.

Though “tree view” provides a nice and clear visualization for structurally simple trees, it is not very compact and requires lots of space when drawing a big family tree. Many family trees also have complex connectivity structure. We found that for large graphs with more than several thousand nodes, standard force directed graph layout algorithm gives good results. We used “organic layout” from yEd graph, editing and visualization software from yWorks, to generate the next several images. Below are examples of medium size trees with several thousand nodes each.
We imagine being able to further analyze the evolution of trees, how trees grow with time, and visualize how customers modifying their trees (trees getting wider and bushier, etc.). Do people make trees “deeper” in generations, or “wider”, among contemporaries? Can we detect results of people making new connections to other living people because of results from DNA testing? So far, this is a work in progress as we study our tree data, and we look forward to finding answers to these questions.