Today we announced that the matching portions of the AncestryDNA test results have been updated. The purpose of this post is to give you a little more detail around the science behind these improvements.
Our previous DNA matching algorithms were based on the AncestryDNA database when it was populated by about half a million people. This latest update is based on three times that many people: 1.5 million. Our larger database has allowed us to make improvements to the matching algorithms. What are those improvements, and how are they going to help the overall matching experience?
Let’s take a look at the current version of the matching pipeline. Below is an image taken from the white paper that highlights this process.
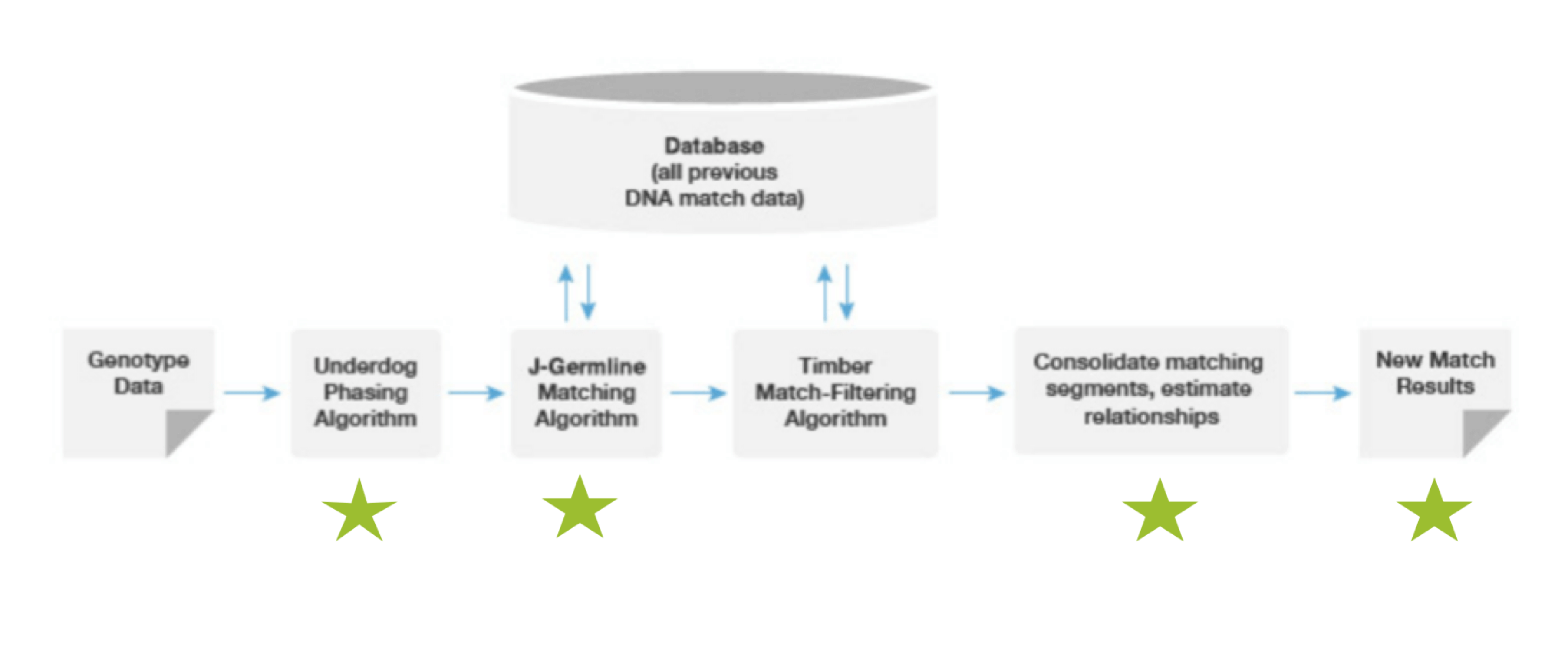
I am not going to take you through each step; instead, I want to focus on where the advances have been made. There are four areas (highlighted by the four stars):
- Phasing—adding more duo- and trio-phased samples
- Matching algorithm—more precise estimates of where each shared segment begins and ends
- Consolidate matching segments—improvements to relationship estimating with a larger database
- New Match results—updated for all existing DNA customers
Individual results may vary, but we believe that the improvements to these four areas will improve the overall matching process for our customers.
Phasing
Phasing refers to the process of computationally determining the assignment of allele copies to chromosomes. In other words, phasing estimates the string of letters of DNA inherited as a unit from each parent. We have now added additional known DNA-tested parent and child (duo sets) and known DNA-tested parents (both) and child (trio sets) to the process to make our phasing even more accurate. You can learn more about the studies we used to prove these methods in section 2.3 of the white paper.
Matching Algorithm
Until now, we were limited to looking at narrow windows across the genome, as we broke it up into small segments. With this update, we don’t need to use the window-based approach anymore. We now use SNPs (single nucleotide polymorphisms) to determine the stop and end points, which lets us measure start and end points of each match segment with more precision.
Consolidate Matching Results
The improved phasing of the genome along with the increased precision in identifying shared segments means our science team can estimate the relationship between DNA matches with more precision. Our findings and validation process have led to new evidence about how much shared DNA people are likely to have across all relationships. See the chart below to see how we determine each level of relationship based on how many centimorgans matches share.

New Match ResultsThe number of centimorgans you share with a match can also help you understand your relationship to them. For example, you’ll usually share about 120 centimorgans with a 3rd cousin, but it’s possible to share as few as 90 or as many as 200. Be aware that the precise amount of shared DNA can vary beyond the ranges shown in the table above.
New match results have been provided for everyone. Whether you tested with AncestryDNA last week or 2 years ago, your results have been recalculated based on these advancements. Because of this, you may see some DNA matches that were previously predicted to be more closely related to you at a higher confidence, drop down on your list, or no longer appear. Also, you’ll have new DNA matches that you haven’t seen before. If you have taken notes or “starred” a DNA match that no longer appears on your new list, you can download information about that previous match from the DNA test settings page. This will be available for a limited time so you should download any such information as soon as you can.
If you are waiting for your results or are in the process of getting a test, your matching results will go through this new procedure as well.
Want to learn more? Check out the matching white paper or the FAQs.