My team has been tasked with providing a dashboard for some of our product teams that enables them to aggregate various monitoring systems, logs, metrics, and other forensic tools into one place.
While provisioning this dashboard, we discovered we needed a tool that could hit an endpoint, run code against the response, record the results, and do it all on a scheduled basis.
I was assigned to build this tool, which, thanks to modern technologies, only took a couple of days and is now a simple, lightweight node.js server.
One passes in a request object (with the url, method, headers, url parameters, etc.), an interval (e.g. 30000 ms), and a script to run against the response. The server schedules the task with the interval given, performs the request, compiles and runs the script against the response, and records the results in SQL Server.
We inserted a dozen or so scheduled tasks, and it has been executing flawlessly for the last two weeks.
For example, here is a graph of the response time of one of our servers over the last hour:
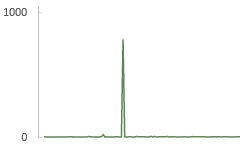
At some point, a response time of over 800 ms was recorded. Sometimes a request can just take a long time and there can be a lot of reasons for it – but if it only happened once, it’s usually not worth taking the time to triage. It is, however, at least worth checking to see if it did only happen once, so here’s a full week:

There are spikes of ~150ms, but nothing anywhere close to a full second. It appears to be an isolated incident, so we’ll chalk it up to gremlins and move on.
With this tool available to us, it’s simple to track response times, uptime, downtime, errors, and anything else we deem interesting.
Tools like these save us a lot of time by keeping an eye on things while we’re busy with other priorities, freeing us up to work on adding new features, polishing existing functionality, and removing bugs from the code base.